
Trong bài viêt này mình muốn giới thiệu với các bạn các kiến thức cần thiết khi làm việc như một Cloud Engineer hay Solution Architect trong dự án mà mình cảm thấy là cần phải biết và hiểu. Đôi khi chỉ đa phần là kiến thức cơ bản, nhưng nếu không hiểu rõ thì sẽ rất dễ nhầm lẫn và đưa ra quyết định sai khi đứng trước những lựa chọn.
Đầu tiên, chúng ta thử tìm hiểu xem mình mong muốn trở thành một người thế nào nhé. Với vai trò của mình, bạn sẽ cần phải đứng giữa Customers/Technical Teams/Manager Teams, để hiểu những ai, cần những gì, vì không phải ai cũng giống nhau. Bạn cần tìm cách xác định thứ mà mỗi bên mong muốn thực sự. Sau khi đã xác định được mục tiêu, bạn cần phải chuyển đổi mục tiêu của bên này (khách hàng) sang bên kia (đội ngũ developer) qua việc phân tích, thiết kế hệ thống … Đây là lúc bạn cần vận dụng rất nhiều kiến thức của bản thân và của cả đội ngũ phát triển để có thể đạt được mục tiêu chung đã đề ra.

Trên đây là 1 số kiểu SA (Solution Architect) Engineer 🐖
- Kiểu “I” (chuyên gia theo định nghĩa cũ) thường là những người có kiến thức ở một lĩnh vực nhất định và đi rất sâu trong lĩnh vực đó.
- Kiểu “ー” (nếu xoay ngang kiểu “I”) đại diện cho một kiểu người hiểu biết trải rộng trên nhiều lĩnh vực, nhưng không có cái nào đi sâu.
- Kiểu “T” (kết hợp giữa kiểu “I” và “ー”) là những người có kiến thức tổng quát ở nhiều lĩnh vực cùng khả năng phát triển thêm các hiểu biết sâu trong một vài lĩnh vực cụ thể. Họ có thể trở thành các short-term chuyên gia khi cần.
- Kiểu “M” (trùm cuối 🤣) không chỉ mang một khối lượng kiến thức chuyên sâu và rộng, còn là nhóm người có rất nhiều kinh nghiệm thực tế. Do có nền tảng vững chắc nên rất dễ học hỏi và đi sâu vào các lĩnh vực mới, lĩnh vực cần thiết do yêu cầu của công việc.
Kiến thức đầu tiên mà mình muốn đề cập, đó là các tiêu chuẩn cam kết ở mức độ sử dụng dịch vụ:
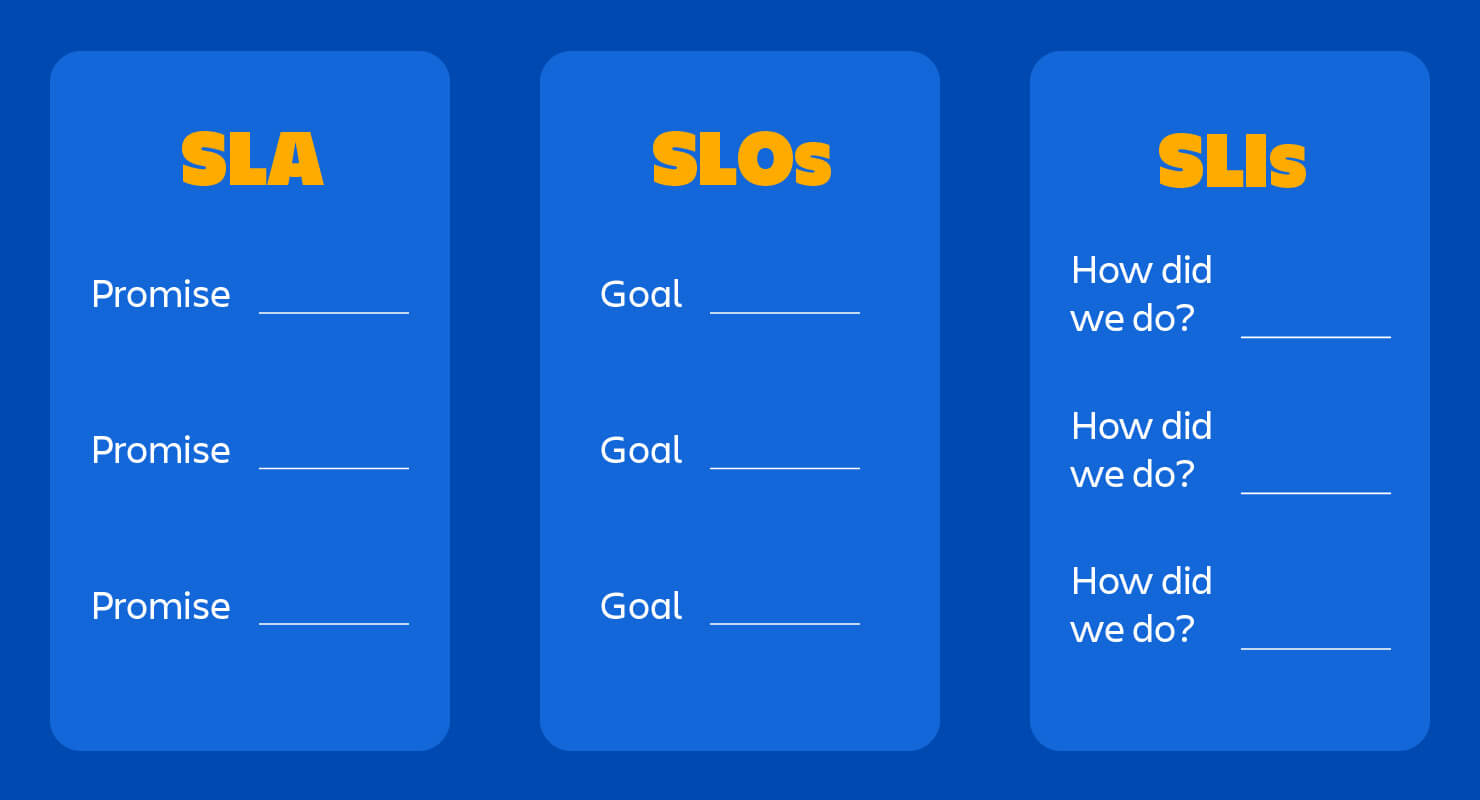
1. SLA, SLO và SLI
-
SLA: Service Level Agreements / Thỏa thuận mức dịch vụLà thỏa thuận giữa nhà cung cấp và khách hàng về các chỉ số có thể đo lường như thời gian hoạt động, khả năng đáp ứng và trách nhiệm. Những thỏa thuận này thường được soạn thảo bởi các nhóm pháp lý và kinh doanh của một công ty và chúng thể hiện những lời hứa mà bạn đang thực hiện với khách hàng — và hậu quả nếu bạn không thực hiện những lời hứa đó. Thông thường, hậu quả thường là hình phạt tài chính, bồi thường tín dụng dịch vụ hoặc gia hạn giấy phép.
Ví dụ: SLA có thể cam kết rằng công ty của bạn sẽ giải quyết các vấn đề được báo cáo với Sản phẩm X trong vòng 24 giờ kể từ lúc vấn đề phát sinh. Và trong trường hợp quá 24h, vấn đề không được giải quyết, bạn sẽ phải bồi thường cho khách hàng một khoảng thời gian hoặc một lượng credit để sử dụng dịch vụ.
-
SLO: Service Level Objectives / Mục tiêu mức dịch vụLà một thỏa thuận trong SLA về một số liệu cụ thể như thời gian hoạt động hoặc thời gian phản hồi. Vì vậy, nếu SLA là thỏa thuận chính thức giữa bạn và khách hàng của bạn, SLO là những lời hứa cá nhân mà bạn đang thực hiện với khách hàng đó. SLO có thể tạo ra nhiều vấn đề nếu chúng mơ hồ, quá phức tạp hoặc không thể đo lường được.
SLA chỉ phù hợp trong trường hợp khách hàng trả tiền, SLO có thể hữu ích cho cả tài khoản trả phí và tài khoản chưa thanh toán, cũng như khách hàng nội bộ và bên ngoài.
-
SLI: Service Level Indicator / Chỉ báo mức dịch vụĐo lường sự tuân thủ với SLO. Ví dụ: nếu SLA của bạn chỉ định rằng hệ thống của bạn sẽ khả dụng 99.95% toàn thời gian, SLO của bạn sẽ là 99.95% thời gian hoạt động và SLI là phép đo thực tế về thời gian hoạt động của bạn. Có thể là 99.96% - Có thể là 99,99%. Để tuân thủ SLA của bạn, SLI sẽ cần phải đáp ứng hoặc vượt quá những lời hứa được đưa ra trong tài liệu đó.
2. RPO và RTO

-
RTO (Recovery time objective): Chỉ định khoảng thời gian cần thiết để hệ thống khôi phục dữ liệu từ các bản sao lưu dự phòng. Ví dụ: nếu RTO hệ thống của bạn là 45 phút, thì mục đích của bạn là khôi phục hoàn tất trong khung thời gian 45 phút đó. -
RPO (recovery point objective): Chỉ định xem dữ liệu sử dụng trong quá trình khôi phục được sử dụng từ thời điểm nào. Nói cách khác, bạn sẵn sàng mất bao nhiêu dữ liệu? Ví dụ: nếu một máy chủ gặp sự cố ngay bây giờ và RPO của bạn là 30 phút, thì tức là bạn có thể khôi phục từ bản sao lưu được thực hiện vào 30 phút trước.
Việc xác định tần suất sao lưu dữ liệu, thời gian phục hồi dữ liệu không chỉ phụ thuộc vào kiến trúc hệ thống của bạn, mà còn phụ thuộc vào góc độ hoạt động kinh doanh của doanh nghiệp. Hãy yêu cầu nhóm điều hành chia sẻ việc kinh doanh sẽ bị ảnh hưởng như thế nào nếu hệ thống gặp lỗi. Hãy để họ quyết định khoảng thời gian chết và mất dữ liệu mà doanh nghiệp có thể chấp nhận.
3. High Availability và Fault Tolerance
-
High Availability / Tính sẵn sàng caoLà sự kết hợp giữa phần mềm và phần cứng để giảm thiểu thời gian chết bằng cách nhanh chóng khôi phục các dịch vụ thiết yếu khi hệ thống, thành phần hoặc ứng dụng bị lỗi. Mặc dù không tức thời nhưng các dịch vụ được khôi phục nhanh chóng, thường trong vòng chưa đầy một phút.
-
Fault Tolerance / Khả năng chịu lỗiLà khả năng phát hiện lỗi và ngay lập tức chuyển sang thành phần hệ thống dự phòng. Mô hình chịu lỗi chủ yếu giải quyết các vấn đề về phần cứng ví dụ bộ xử lý, bo mạch bộ nhớ, bộ nguồn, hệ thống con I/O hay hệ thống con lưu trữ.

Hãy tưởng tượng đơn giản như sau: High Availability / Tính sẵn sàng cao tương đương với việc bạn đi 1 chiếc xe và có bánh xe dự phòng, khi hỏng bánh bạn có thể dừng lại và thay bánh khác. Còn Fault Tolerance / Khả năng chịu lỗi tương đương với việc bạn đang sử dụng máy bay, lỡ như có 1 động cơ hỏng thì máy bay vẫn phải tiếp tục bay được bằng các động cơ còn đang hoạt động. Rõ ràng, sự khác biệt giữa khả năng chịu lỗi và tính sẵn sàng cao, đó là: Môi trường có khả năng chịu lỗi không có gián đoạn dịch vụ nhưng chi phí cao hơn đáng kể, trong khi môi trường khả dụng cao có sự gián đoạn dịch vụ tối thiểu.
4. MB, Mb và MiB
Nghe 3 từ này thì có vẻ giống hệt nhau nhưng chắc chắn một điều là không !!!. Trước hết bạn cần nắm được các term trên là viết tắt của từ gì:

MB=Megabyte- Megabyte (MB) là một thuật ngữ dùng để nói về khả năng lưu trữ dữ liệu của các phần cứng chuyên dụng như ổ đĩa 500MB, ổ đĩa 1024MB (1GB), 2048 MB (2GB), …
Mb=Megabit- Megabit (Mb) lại hay dùng để nói về chuyện truyền tải dữ liệu, chúng ta thường rất hay gặp Mbps (Megabit per second) được hiểu là tốc độ truyền dữ liệu trên mỗi giây.
- Ví dụ, tốc độ Internet của bạn là 15.5Mbps, có nghĩa là 15.5 Megabit đang được truyền đi mỗi giây.
- Megabit (Mb) lại hay dùng để nói về chuyện truyền tải dữ liệu, chúng ta thường rất hay gặp Mbps (Megabit per second) được hiểu là tốc độ truyền dữ liệu trên mỗi giây.
MiB=Mebibyte(Đôi lúc có thể viết làMIB)- Mebibyte là một bội số của đơn vị byte trong đo lường khối lượng thông tin số. Tiền tố nhị phân mebi nghĩa là \(2^{20}\), bởi vậy \(1 \text{ mebibyte} = 2^{20} = 1048576 \text{ bytes} = 1024 \text{ kibibyte}\).
- Đơn vị này được giới thiệu bởi International Electrotechnical Commission (IEC) năm 1998 nhằm thay thế megabyte, được sử dụng trong nhiều bối cảnh để đại diện cho \(2^{20}\) byte, thay cho định nghĩa của tiền tố mega của International System of Units (SI) là bội số của \(10^6\) byte.
- Mebibyte là một bội số của đơn vị byte trong đo lường khối lượng thông tin số. Tiền tố nhị phân mebi nghĩa là \(2^{20}\), bởi vậy \(1 \text{ mebibyte} = 2^{20} = 1048576 \text{ bytes} = 1024 \text{ kibibyte}\).
Để rõ hình dung hơn, chúng ta có các công thức về mối tương quan như sau:
- 1 Byte = 8 Bits
- 1 Megabyte = 1,000,000 Bytes
- 1 Megabit = 1,000,000 Bits == 125,000 bytes
- 1 MebiByte = \(2^{20}\) Bytes = 1,048,576 Bytes
- 1 Megabyte = 8 Megabit
Mặc dù 12.5MB = 8*12.5 = 100Mb, nhưng xét về góc độ kinh doanh, nếu cùng một gói cước mạng viễn thông, nhà cung cấp quảng cáo “gói cước mạng 100 Mbps” thay vì “gói cước mạng 12.5 MBps” rõ ràng khách hàng nào không hiểu sẽ thấy con số 100 trông ấn tượng hơn rất nhiều, một thủ thuật nhỏ nhưng mang lại hiệu quả maketing vô cùng lớn, giúp thu hút được nhiều khách hàng hơn. 💯
5. Latency, Bandwidth, Throughput và Response Time
Latency, Throughput, Bandwidth và Response Time Là những thuật ngữ rất dễ hiểu nhầm. Hãy cùng nhìn vào hình minh hoạ bên dưới, chúng ta có một bể nước (Màu cam), ống nước (Màu xanh lá cây), nước (Màu xanh lam). Bể chứa nước đại diện cho một máy chủ, đường ống đại diện cho communication channel (kênh truyền thông) với độ rộng nhất định và nước đại diện cho dữ liệu. Tất cả bốn thuật ngữ quan trọng: Latency (Độ trễ), Bandwidth (Băng thông), Throughput (Thông lượng) và Response Time (Thời gian đáp ứng) sẽ được giải thích với sơ đồ này.
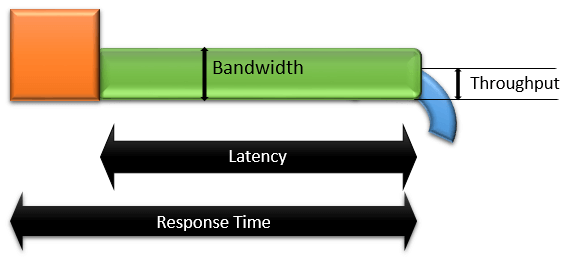
Latency: Thời gian mà nước đi từ đầu này đến đầu kia được gọi là Độ trễ. Thuật ngữ độ trễ (hay tốt hơn được gọi là Độ trễ mạng) của một yêu cầu là thời gian di chuyển từ máy khách đến máy chủ và máy chủ đến máy khách.- Một yêu cầu bắt đầu từ t = 0
- Tiếp cận máy chủ sau 1 giây (tại t = 1)
- Máy chủ mất 2 giây để xử lý (tại t = 3)
- Tiếp cận máy khách kết thúc sau 1,2 giây (tại t = 4)
- Vì vậy, độ trễ mạng sẽ là 2,2 giây (= 1 + 1,2).
Bandwidth: Băng thông thể hiện dung lượng của đường ống (kênh truyền thông). Nó cho biết lượng nước tối đa đi qua đường ống. Lượng dữ liệu tối đa có thể được truyền trên một đơn vị thời gian thông qua một kênh truyền thông được gọi là băng thông của kênh.- Giả sử ISDN có băng thông 64Kbps và chúng ta có thể tăng nó bằng cách thêm một kênh 64Kbps nữa, vì vậy tổng băng thông sẽ = 128Kbps, do đó dữ liệu tối đa có thể được truyền qua kênh ISDN = 128Kbps.
Throughput: Nước chảy ra từ đường ống có thể được biểu thị là ‘Thông lượng’. Định nghĩa: Lượng dữ liệu được di chuyển thành công từ nơi này sang nơi khác trong một khoảng thời gian nhất định được gọi là Thông lượng dữ liệu.- Nó thường được đo bằng bit trên giây (bps), như megabit trên giây (Mbps) hoặc gigabit trên giây (Gbps).
Response Time: Là khoảng thời gian kể từ thời điểm người dùng gửi yêu cầu cho đến thời điểm ứng dụng cho biết rằng yêu cầu đã hoàn thành và liên hệ lại với người dùng. Trong ví dụ Độ trễ, Thời gian phản hồi sẽ là 4 giây.
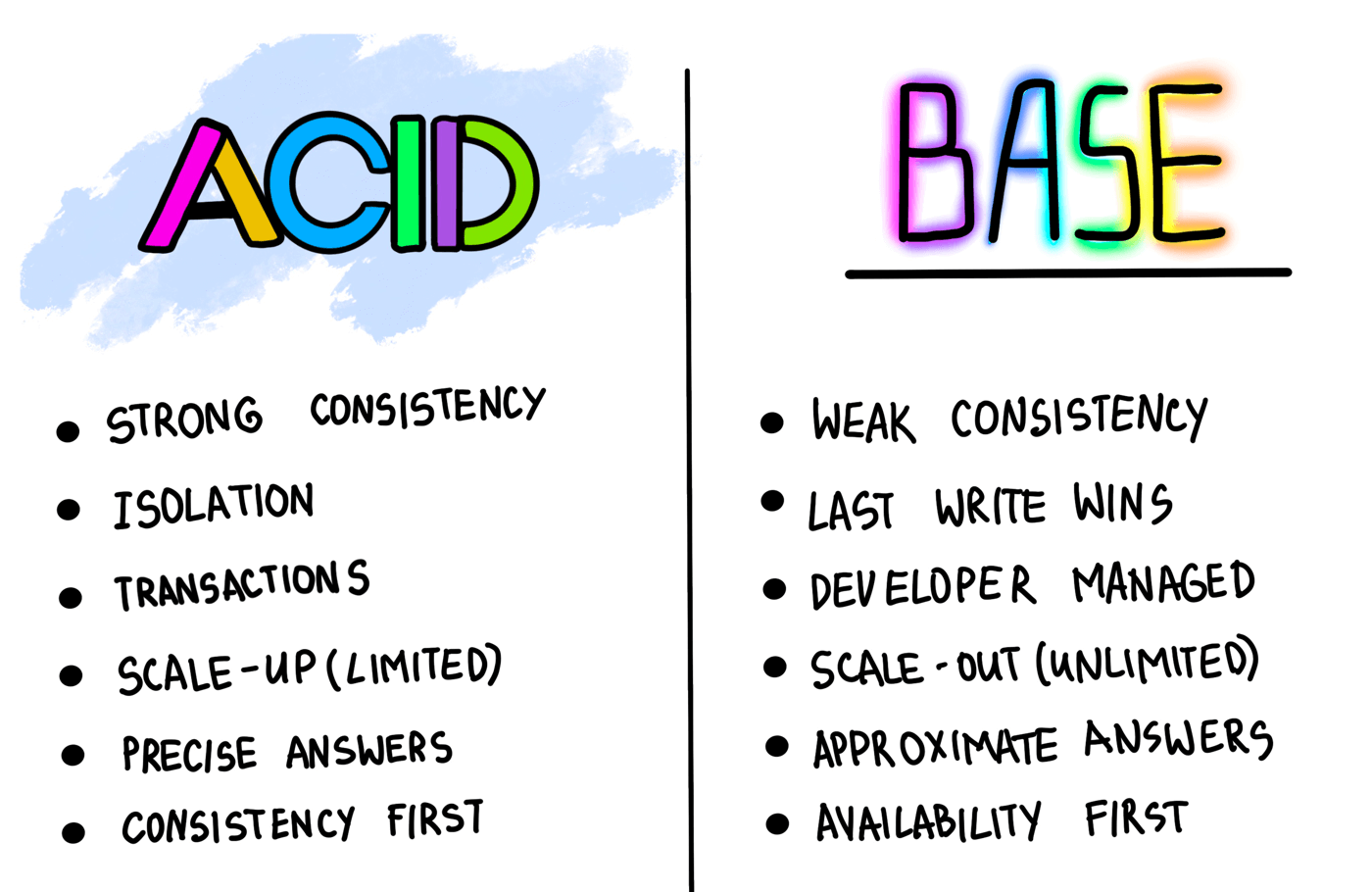
6. ACID và BASE
- ACID Consistency Model
- Atomic: Tất cả các operations trong một transactions thành công hoặc tất cả operations được rollback. Hay nói cách khác mỗi giao dịch sẽ được thực hiện hoàn toàn hoặc không. Không có trạng thái trung gian nào được phép.
- Consistent: Khi transaction hoàn thành, cấu trúc cơ sở dữ liệu ổn định. Tính nhất quán là một yêu cầu ngụ ý rằng giao dịch sẽ dẫn đến dữ liệu hợp lệ. Ví dụ: số tiền trong tài khoản không được là giá trị âm. Mỗi giao dịch thành công, theo định nghĩa, chỉ thu được các kết quả hợp lệ.
- Isolated: Các transaction là cô lập nhưng khi truy xuất dữ liệu sẽ đảm bảo tính tuần tự. Các sự kiện xảy ra trong một giao dịch phải được ẩn khỏi các giao dịch đồng thời khác. Nếu điều kiện này không được đáp ứng thì giao dịch sẽ không thể rollback (Atomicity).
- Durable: Khi một giao dịch đã hoàn thành và cam kết kết quả của nó với cơ sở dữ liệu, hệ thống phải đảm bảo rằng những kết quả này vẫn tồn tại sau bất kỳ lỗi nào tiếp theo.
- Thuộc tính ACID có nghĩa là khi một giao dịch hoàn tất, dữ liệu của nó nhất quán và ổn định trên bộ nhớ. Các database tuân thủ ACID thường là relational database như MySQL, PostgreSQL, Oracle, SQLite, Microsoft SQL Server.
- BASE Consistency Model
- Basic Availability: Hệ thống tập trung vào tính khả dụng của dữ liệu ngay cả khi dữ liệu có lỗi hoặc không nhất quán. Điều này đạt được bằng cách sử dụng cách tiếp cận phân tán. Thay vì duy trì store lưu trữ dữ liệu lớn và tập trung vào khả năng chịu lỗi của store đó, dữ liệu được phân phối trên nhiều hệ thống lưu trữ với mức độ sao chép cao.
- Soft-state: Store không cần phải nhất quán về mặt ghi, cũng như các replicas cần đảm bảo tính nhất quán toàn thời gian.
- Eventual consistency: Tính nhất quán được thể hiện sau cùng ở store, ví dụ: Lazy read at time. Yêu cầu duy nhất mà các hệ thống có đối với tính nhất quán là dữ liệu phải hội tụ về trạng thái nhất quán vào một thời điểm nào đó trong tương lai. Tuy nhiên, không có gì đảm bảo khi nào điều này sẽ xảy ra. Điều này hoàn toàn trái ngược với yêu cầu nhất quán tức thì của ACID, yêu cầu này cấm thực hiện một giao dịch cho đến khi giao dịch trước đó hoàn tất và cơ sở dữ liệu được hội tụ về trạng thái nhất quán.
- Đối với cơ sở dữ liệu dạng BASE, tính khả dụng được đặt lên hàng đầu. Tuy nhiên tính nhất quán không được đảm bảo trên tất cả các replicas. Nhìn chung, mô hình nhất quán BASE cung cấp sự đảm bảo ít nghiêm ngặt hơn so với ACID: dữ liệu sẽ nhất quán trong tương lai.
- Cũng giống như cơ sở dữ liệu SQL gần như toàn bộ tuân thủ ACID, cơ sở dữ liệu NoSQL có xu hướng tuân thủ các nguyên tắc BASE. MongoDB, Cassandra và Redis là một trong những giải pháp NoSQL phổ biến nhất, cùng với Amazon DynamoDB và Couchbase.
Thành thật mà nói, tôi thấy khái niệm BASE là mang tính tiếp thị hơn ACID - bởi vì nó không đưa ra bất kỳ điều gì mới và không đặc trưng cho cơ sở dữ liệu theo bất kỳ cách nào. Sau khi biết về nó bạn có thể quên nó đi cũng OK 😂
7. Input/Output Operations Per Second (IOPS)
Các Cloud Provider như AWS, GCP thường đo lường hiệu suất của storage bằng số thao tác thực hiện input/output trên đơn vị thời gian là giây. Input/Output (I/O) operation là các hành động đọc và ghi dữ liệu vào bộ nhớ. Dĩ nhiên, storage của bạn càng đạt được nhiều IOPS, thì cơ sở dữ liệu của bạn có thể lưu trữ và truy xuất dữ liệu càng nhanh.
Với AWS RDS, Amazon phân bổ cho bạn một số IOPS tùy thuộc vào loại storage bạn chọn và bạn không thể thiết lập vượt quá ngưỡng này. Tốc độ lưu trữ cơ sở dữ liệu của bạn bị giới hạn bởi số lượng IOPS được phân bổ cho nó. Lượng dữ liệu bạn có thể truyền trong một thao tác I/O duy nhất phụ thuộc vào kích thước trang (page size) mà công cụ cơ sở dữ liệu sử dụng. Để hiểu bạn cần bao nhiêu IOPS, trước tiên bạn cần hiểu thông lượng (throughput) đĩa bạn cần là bao nhiêu.
- Ví dụ: MySQL và MariaDB có page size = 16 KB. Do đó, ghi 16 KB dữ liệu vào đĩa tương đương với 1 I/O operation. Trong khi Microsoft SQL Server sử dụng page size = 8 KB. Ghi 16 KB dữ liệu tương đương với 2 I/O operaions.
- Page size = 16 KB, và bạn cần đọc 102,400 KB (100 MB) dữ liệu mỗi giây → Bạn cần thực hiện 102,400 / 16 = 6,400 IOPS.
- Kích page size của bạn càng lớn, bạn cần ít IOPS hơn để đạt được cùng một mức thông lượng. Tuy nhiên điều gì sẽ xảy ra nếu Database Engine của bạn sử dụng page size >= 32 KB ? Với AWS cloud, mọi page size >= 32 KB sẽ được tính >= 1 I/O operaion. Chẳng hạn read hoặc write 1 page size 64 KB được tính là 2 I/O operations, 128 KB được tính là 4 I/O operations.
8. CPU Credit, Burstable và Baseline
Khái niệm này chỉ dành riêng cho AWS Cloud, Instance EC2 truyền thống cung cấp 1 lượng tài nguyên CPU là cố định, trong khi Burstable performance instances cung cấp mức sử dụng CPU cơ bản (baseline) tuy nhiên cho phép được sử dụng vượt quá mức sử dụng cơ bản này. Điều này đảm bảo rằng bạn chỉ phải trả cho CPU cơ bản + bất kỳ mức sử dụng CPU vượt quá bổ sung nào, giúp tiết kiệm chi phí tối đa.
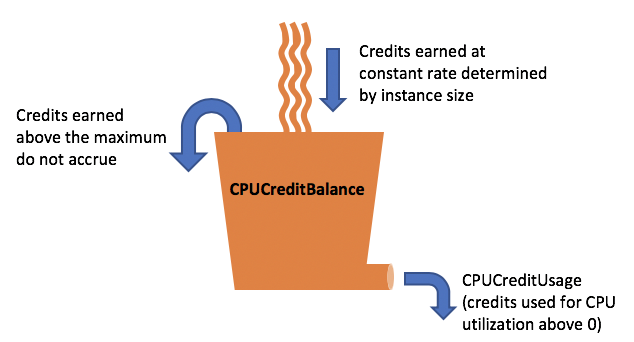
Việc sử dụng baseline hay burstable được quản lý bởi 1 chỉ số có tên là CPU credit. Và số credit này cũng không phải là một con số cố định, Mỗi phiên bản Burstable performance instances có thể kiếm được credit khi nó sử dụng dưới mức cơ bản (baseline) của CPU và tiêu hao credit khi nó sử dụng quá mức cơ bản (baseline). Số lượng credit kiếm được hoặc tiêu hao phụ thuộc vào việc sử dụng CPU của phiên bản:
- Nếu việc sử dụng CPU dưới mức cơ bản, thì credit kiếm được > credit đã chi tiêu.
- Nếu việc sử dụng CPU bằng với mức cơ bản, thì credit kiếm được = credit đã chi tiêu.
- Nếu mức sử dụng CPU cao hơn mức cơ bản, thì credit đã chi tiêu sẽ > credit kiếm được.
Quy luật trên được mô tả tương tự một chiếc thùng chứa nước (credit), ở vòi nước chính là mức sử dụng hay tiêu hao credit CPU. Toàn bộ lượng nước khi thùng chứa đầy có thể coi là mức CPU cơ bản (baseline).
Kiến thức thì còn rất nhiều, mình sẽ cố gắng tổng hợp thêm trong các bài viết sau.